Tiansheng Wen

There is a crack in everything,
that's how the light gets in.✨
I am Tiansheng Wen, a first-year Ph.D. student at Georgia Tech, advised by Prof. Pan Li.
My research broadly lies in core machine learning, especially sparsity, with applications to LLMs and LLM-driven agentic learning. Recently, I have been mainly focusing on:
- Token sparsity in on-policy distillation.
- Sparse and structured representations for edge-friendly scalable retrieval.
- Agentic learning for structured data.
Before joining Georgia Tech, I spent seven wonderful years at Xidian University for my B.S. and M.S. degrees, where I was fortunate to be supervised by Prof. Bo Chen.
I also spent an incredible year at Stony Brook University working with Prof. Chenyu You. I am deeply grateful to my close collaborators, Prof. Stefanie Jegelka and Yifei Wang, for our work on efficient and scalable sparse methods.
I am actively open to research collaboration. Feel free to reach out!
news
| May, 2026 | No more K-means! Our paper Single-Stage Sparse Multi-Vector Retrieval (SSR) was accepted to ICML 2026, showing how sparse codes can naturally organize token-level matches for faster, fine-grained retrieval without a separate clustering step. 🎉🎉 |
|---|---|
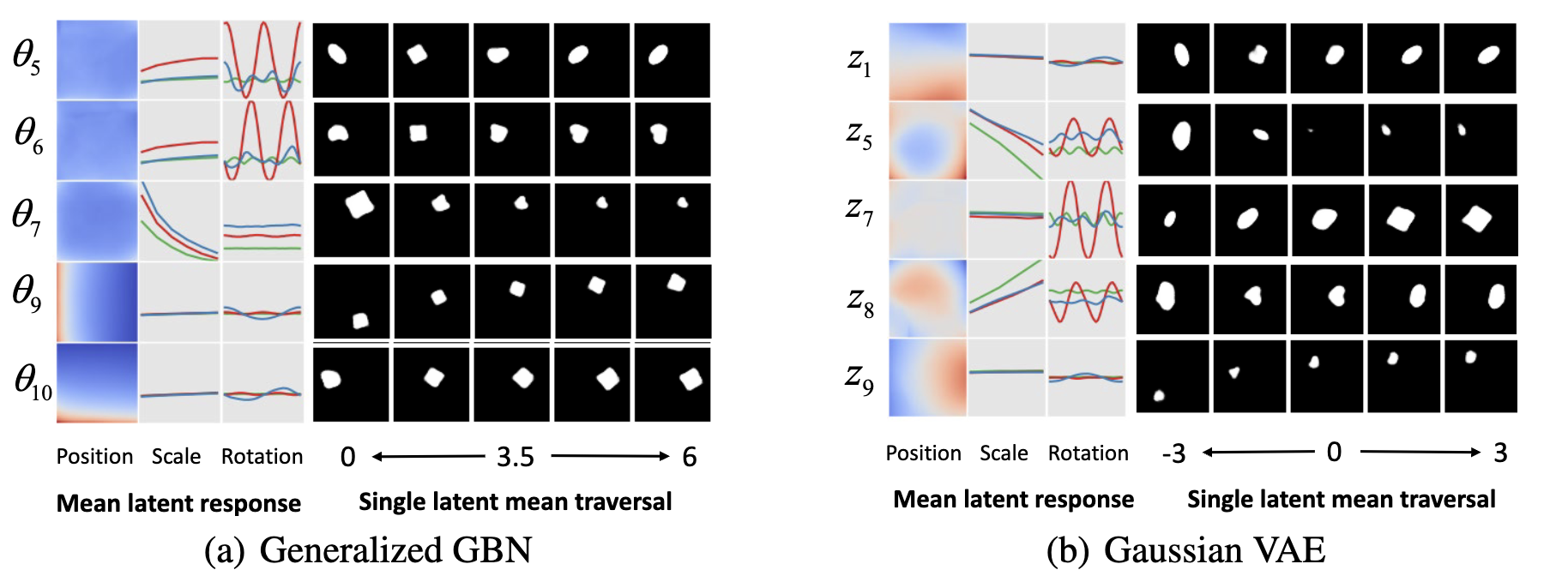
| Mar, 2026 | Thrilled to share that our paper A Non-negative VAE: the Generalized Gamma Belief Network has been accepted by IEEE TPAMI! 🎉🎉 |
| Mar, 2026 | A new chapter begins! Beyond excited to join Georgia Institute of Technology as a PhD student this Fall! Atlanta, I’m coming! Go Jackets! 🐝✨ |
| Feb, 2026 | One paper accepted at TCSVT! First benchmark for multimodal remote sensing detection under real-world cloud degradations.🎉🎉 |
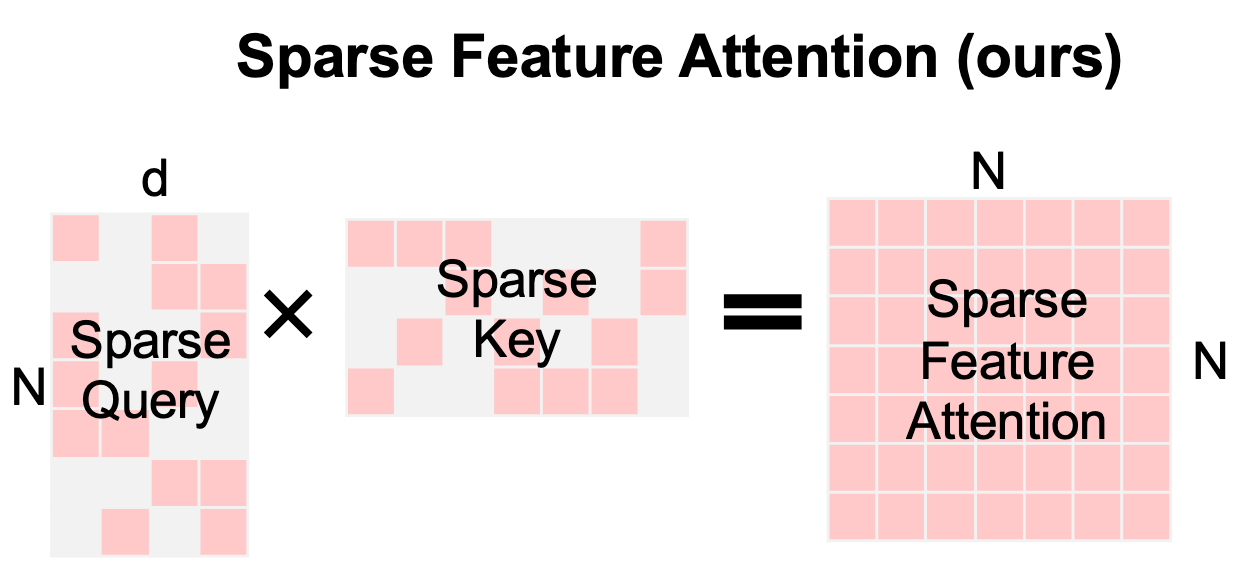
| Jan, 2026 | New members in sparsity family! Two papers on ultra-sparse embeddings and sparse feature attention accepted at ICLR 2026. Catch us in Rio de Janeiro!🌊🐚 |
| Oct, 2025 | Join ByteDance Bandai as a Research Intern, targeting Agentic RL!⚡️️⚡️ |
| Jul, 2025 | The wait is over! CSR is now available in Sentence-Transformer v5.0! 🤗🤗 |
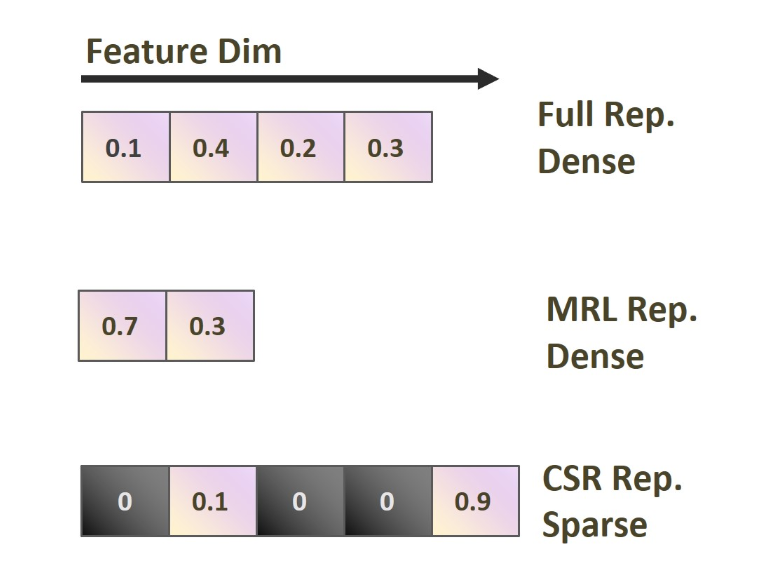
| May, 2025 | Our paper Contrastive Sparse Representations (CSR) was selected for an Oral Presentation (Top 1%) at ICML 2025! CSR compresses SOTA 4k-dim embeddings to just 32 active dimensions, achieving ~100× faster retrieval for RAG and vector databases with minimal accuracy loss.🏆🏆 |
| Mar, 2025 | Our recent work Contrastive Sparse Representation has generated considerable interest as a promising alternative approach for efficient embedding retrieval, and we have been invited to publish the model on Hugging Face and Sentence-Transformer! Code available at Link. 🤗🤗 |
| Feb, 2025 | Our paper LanCE has been accepted by CVPR 2025! 🎉🎉 |
| Jul, 2024 | Our paper HICE-Score has been accepted by CVPR 2025! 🎉🎉 |