Tiansheng Wen

There is a crack in everything,
that's how the light gets in.✨
I am Tiansheng Wen, a Research Intern at ByteDance-BandAI. My research focuses on enhancing the scalability and reliability of LLMs through structural and post-training sparsity, empowering agents to tackle complex real-world tasks like coding efficiently without compromising general performance.
I am a final-year M.S. student at Xidian University, advised by Prof. Bo Chen. I spent a wonderful year at Stony Brook University working with Prof. Chenyu You. I also collaborate closely with Prof. Stefanie Jegelka and Yifei Wang on efficient and scalable sparse methods.
I’m an incoming PhD student at Georgia Institute of Technology, advised by Prof. Pan Li. I am actively open to research collaboration. Feel free to reach out!
news
| Mar, 2026 | Thrilled to share that our paper A Non-negative VAE: the Generalized Gamma Belief Network has been accepted by IEEE TPAMI! 🎉🎉 |
|---|---|
| Mar, 2026 | A new chapter begins! Beyond excited to join Georgia Institute of Technology as a PhD student this Fall! Atlanta, I’m coming! Go Jackets! 🐝✨ |
| Feb, 2026 | One paper accepted at TCSVT! First benchmark for multimodal remote sensing detection under real-world cloud degradations.🎉🎉 |
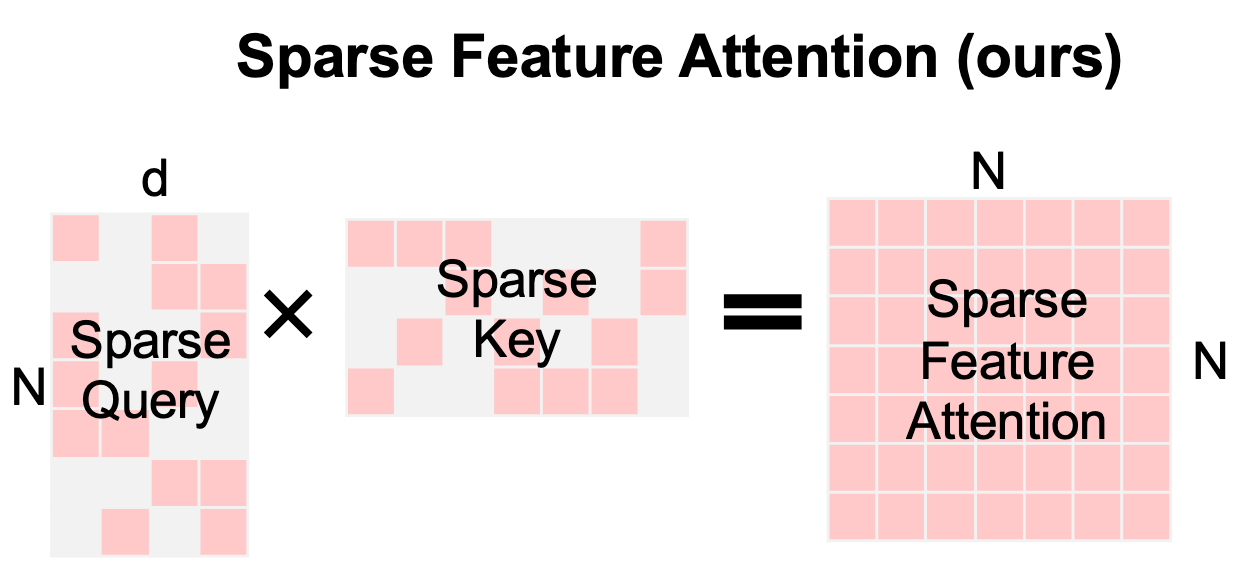
| Jan, 2026 | New members in sparsity family! Two papers on ultra-sparse embeddings and sparse feature attention accepted at ICLR 2026. Catch us in Rio de Janeiro!🌊🐚 |
| Oct, 2025 | Join ByteDance Bandai as a Research Intern, targeting Agentic RL!⚡️️⚡️ |
| Jul, 2025 | The wait is over! CSR is now available in Sentence-Transformer v5.0! 🤗🤗 |
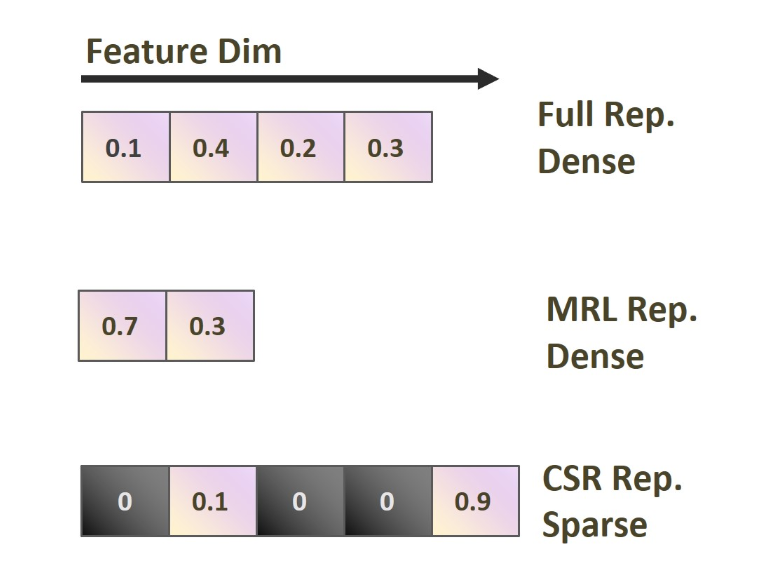
| May, 2025 | Our paper Contrastive Sparse Representations (CSR) was selected for an Oral Presentation (Top 1%) at ICML 2025! CSR compresses SOTA 4k-dim embeddings to just 32 active dimensions, achieving ~100× faster retrieval for RAG and vector databases with minimal accuracy loss.🏆🏆 |
| Mar, 2025 | Our recent work Contrastive Sparse Representation has generated considerable interest as a promising alternative approach for efficient embedding retrieval, and we have been invited to publish the model on Hugging Face and Sentence-Transformer! Code available at Link. 🤗🤗 |
| Feb, 2025 | Our paper LanCE has been accepted by CVPR 2025! 🎉🎉 |
| Jul, 2024 | Our paper HICE-Score has been accepted by CVPR 2025! 🎉🎉 |